
传参(Pass by Value)
我们都知道 C 语言参数传递的机制是通过函数调用,获得实参 exp 的返回值 <V, V_T>,然后将 V 写入到被调用函数的形参 Argument_Name 对应的内存中去。在这个传参过程中,V_T 和 Argument_Type 必须适配。因此,需要注意的其实就是函数参数为非数组变量或数组变量时,传入的 <V, V_T> 的问题,而这个问题已经在之前讲表达式的值 的时候解决了(其实就是那几个计算原则倒来倒去)。
这里还可以解释数组作为函数参数时第一维信息丢失的现象。由于数组类型传入的 V_T 取的是数组元素的指针类型,所以总会丢失第一维——第一维信息丢失的原因是 C 语言所有数组类型变量内存的取值机制。
借思考题巩固一下就好了:

进一步了解 malloc
返回的指针类型
之前讲内存的六元组模型的时候,我们提过一嘴,由 malloc 分配的内存是没有变量名称的,它的六元组模型里已知的只有 Address 和 Size,其他都是 N/A,故这块内存显然没办法通过变量名进行定位使用,想要访问 malloc 分配的内存,只有通过指针(也就是 * 运算符)了。
由于未知六元组模型中的任何一种 Type,显然需要对这个指针的类型做出一些限制,换言之,就是对 malloc 的返回值类型做限制。
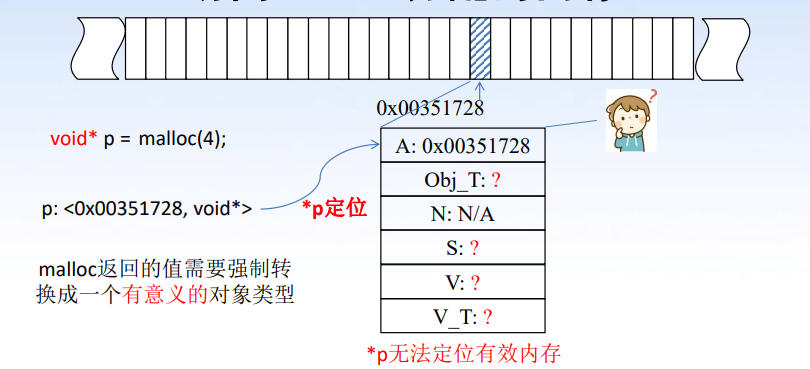
首先,如上图所示,指针需要能够定位有效内存,因此 malloc 的返回值类型应当是有意义的。将上图中的 void* p = malloc(4) 替换成 int* p = (int*) malloc(4) 就自然多了。
然而,我们选取类型的时候,还需要考虑该类型是否与 malloc 的 Size 匹配,比如,如果我们把 malloc(4) 的返回值强转成 double* 的话,那返回的那个指针的 Value 值就没法确定了(或者说是错误的)。因此,我们经常使用 sizeof 来计算待分配空间大小,防止出现这种情况,形式化地表述就是 malloc 的经典使用方法:
Obj_T* p = (Obj_T*)malloc(sizeof(Obj_T) * N);
理解经典使用方法
对于上一节中给出的经典使用方法:
Obj_T* p = (Obj_T*)malloc(sizeof(Obj_T) * N);
可以将其理解为,使用 malloc 申请了 N 个连续的 Obj_T 空间,那么语义上可以视为申请了一个 Obj_T[N] 的空间(一维数组)。根据数组类型变量的返回值类型计算原则,该空间的表示值类型刚好就应该是 Obj_T*,这样一切都串起来了。
显然,这种方法也可以直接用来分配高维数组。只不过分配高维数组的时候需要把维度数字写死在程序里,工程扩展性比较差,因此 malloc 还是更常用于分配一维数组,还有用下面这种方式分配二维数组:

通过这个规则,我们可以知道,malloc(sizeof(Obj_T)) 隐含的语义是分配了一个 int[1] 类型的空间,其返回值类型为 Obj_T* 依旧是符合直觉的,只是需要阐明背后的原理。
通过变量声明分配出来的内存不需要释放,但 malloc 分配的内存需要用 free 进行释放(free 函数的参数是 malloc 返回的指针),执行了多少次 malloc,就需要执行多少次 free 操作,否则会造成内存泄漏(Memory Leak)。事实上,内存泄漏至今是软件工程中恒久的挑战,在很多成熟的大项目里依然不断被人找出内存泄漏的 bug。在这里,程序分析就有用武之地了(又串起来了草)。
限定符
对象类型可以附加 const, volatile, restritct, _Atomic 等限定符,前面我们谈到过,加上了限定符以后,Obj_T const / const Obj_T 也是一种对象类型,将其当成一个整体看待就可以。
不同的限定符之间可以组合,比如可以写出 int const volatile a = 10 这样的语句,此时需要组合它们修饰内存的特性。
const
不管是哪个限定符,限定符修饰的是那块内存,并不会修饰值本身。举例而言就是这样:



针对最后一张图,const int 同理,也当成一个整体来看。
“const 修饰的是那块内存” 的含义是,当我们试图修改所有被 const 修饰过的内存时都会导致编译错误。举例而言,假如我们设置 int* const p = &a,那么 p = NULL 的操作就无法通过编译;然而,如果是 int const* p = &a 的话就可以。诀窍只有一个,就是把 Obj_T const / const Obj_T 看成一个整体 / 新的对象类型。所有适用于对象类型的运算原则 / 属性等都适用于它。
实践的时候要是搞不清楚可以用 typedef 之类的操作给它换个别名,比如 typedef const int CINT。
C 语言标准中对 const 位置的摆放没有明确的语义规范,一般来说推荐使用 Obj_T const N 的形式,把 const 放到后面,不然有可能造成很丑的嵌套。
volatile
关于类型的讨论,都跟 const 一样,把 Obj_T volatile / volatile Obj_T 看成一个新类型处理就可以了。这里只讨论内存的事。
volatile 修饰内存的值可能会以 未知 的方式发生变化,这与其特殊的应用场景有关,下面分类讨论。
MMIO 端口对应的对象
MMIO(Memory-Mapped Input/Output)中,内存和 I/O 设备共享同一个地址空间,内存会给各种 I/O 设备预留出相应的地址区域,因此一个地址可能访问内存,也可能访问某个 I/O 设备。我们用 volatile 修饰的对象值很有可能因为硬件的行为而改变,这种改变对于程序来说是 不可知 的。
比如此时外连一个温度传感器记录温度数值,外界温度的变化就可能把内存中某块地址空间里的值改变了,可能会影响到我们的变量。
这一点还会对编译优化造成影响。参考如下代码:
1 | int MYNUM = 10; |
如果要 evaluate 一个 volatile 对象(关于 evaluate 的知识参考表达式的 evaluation 那篇博文),都必须去访问对应的内存,而这块内存的值不确定,故上面第二个 while block 编译器不敢优化。因此,在使用 volatile 的时候我们应当保持 抽象机 的代码规则,即不考虑优化。
不过这里有一个例外,就是如果编译器能推断出一个表达式一定无效(比如把上面的条件改成 MYNUM < 0),也可以选择不 evaluate 这个表达式,即使这个表达式包括 volatile 的对象,这里就可以发掘出一定的优化时机。
这种不确定性给 volatile 修饰的对象带来了强烈的副作用(关于 evaluate 中副作用确定的知识参考表达式的 evaluation 那篇博文)。C 语言规定:
An access to an object through the use of an lvalue of volatile-qualified type is a volatile access.
A volatile access to an object, …., are all side effects.
因此,形如 int a = MYNUM + MYNUM 的表达式都是未定义行为。
异步终端函数访问的对象
这里涉及到多线程问题,事实上笔者第一次遇到 volatile 也是在多线程场景中。但 volatile 和多线程没有必然联系,多线程下共享对象发生的“未知”变化并不是 “unknown” 的,而是程序员没有设计合理的访问控制导致的。在我看来,在多线程场景中使用 volatile 像是利用了 volatile 的宽容,即用它这种“可能会发生未知修改”的特性给多线程场景下的奇怪现象做一种概念上的开脱。
在某些特定的应用场景中,通过volatile可能刚好可以实现需求,但这同时也可能会为软件未来的迭代更新埋下隐患。
这里的经典问题是读写冲突。如果一个表达式试图修改一段内存中的值,其他表达式试图读或写同一块内存,就构成了一个冲突(Conflict)。具体的内容到操作系统和面向对象编程中去复习就好了 hhh 。
restrict
restrict 限定符只能用来修饰 指针 。通过被 restrict 修饰符修饰的指针访问的对象与该指针有一种特殊的关联,这种关联要求所有对该对象的访问都直接或间接地使用该特定指针的值。比如:

涉及过编译器中端优化的看到这个描述可能会很兴奋,因为这非常有利于指针分析啊!要是所有的指针变量都这样那根本就不用为指针分析伤神了,编译器可以直接忽略掉使用 restrict 时产生的任何别名问题!事实也是如此,使用 restrict 的目的就是 促进优化 。
这里引入一个 based on 的概念:对于一个指针表达式 E,如果修改对象 P,使其指向它之前指向的 数组对象 的副本,会改变 E 的值,则我们称指针表达式 E 是基于对象 P 的(based on object P)。
-
可见,指针蕴含着 数组 的意味
-
之前在左值与表达式那一节讲 exp[n] 的时候就提过,任何一个返回值为指针的表达式,蕴含着指向的那块内存为一个数组,元素为指针变量类型对应的变量类型,但大小未知。
-
比如,表达式 p 和 p + 1 是 based on p 对应的对象,但 *p 和 p[1] 不是
-
需要注意的是,E 依赖于 P 本身,而不是通过 P 间接引用的对象的值。
为什么要引入 Based on 呢?可以观察下面的例子:
1 | void func(int n, int * restrict p, int * restrict q) { |
restrict 中蕴含的 based on 特性保证了 p based on 的那个对象只能由 p 来访问,而不会由 q 访问,这样编译器就不必再去做指针分析了。而这也导致 restrict 的语义需要程序员来严格保证,比如上示代码中对 func 的第二次调用,由于两块指向的区域产生重叠且被修改,因此是未定义行为。
size、padding 和 alignment
size 的内涵
给定一个完全对象类型 T,声明一个变量 O(即 T O),其语义是分配一系列字节,这段内存的对象类型为 T,且用 O 这个变量名(标识符)可以定位,O 本身并不是对象,这段内存才是。
因此, sizeof(T) 返回值的含义是为一个类型 T 的对象分配空间需要多少个字节; sizeof(O) 返回值的含义是用变量名 O 来定位的那个对象供占用了多少个字节。
padding
padding 在 CSS 里是边距的意思,我觉得用来理解很方便。不难猜出,padding 是为了服务 对齐 产生的,尤其是结构体 padding。
结构体
此处的具体内容可以参见下文中 alignment 章节对结构体的讨论。
C 语言结构体中的每个成员都需要按照相应的大小进行内存对齐,编译器会在结构体成员之间插入 padding 字节来保证每一个成员都能够以对应的数据大小对齐。padding 区域的存储字节对程序员来说是不可见的,对整个结构体的初始化赋值不会改变 padding 区域的值。简单地使用初始化赋值方法清零结构体区域无法使 padding 区域清零,如果需要确保所有的区域都设置为 0 可以使用 memset 。
可以使用 gcc 的扩展语法阻止 padding,代码如下:
1 | __attribute__((packed)) |
上述功能为 gcc 的扩展语法,它会告诉编译器不要插入 padding 字节,这样可能会造成成员变量的地址不对齐,是一个潜在的安全隐患。对于不支持非对齐访问的处理器而言,结构体成员变量的未对齐地址可能会造成总线错误,导致程序异常终止,也可能会读到变量的部分值。
针对单一变量也需要考虑 padding:
无符号整数
假设一个无符号整数类型 T 一共占用 n × CHAR_BIT 个 bit 位,则 sizeof(T) 的返回值是 <n, size_t>。这 n × CHAR_BIT 个 bit 分为 value bits 和 padding bits 两部分。
假设 value bits 的个数是 N,则该无符号整数对象表值范围为 ,这个 N 值被称为这个无符号整数类型 T 的宽度。可见,无人在意的 padding bits 不起什么实质性作用,仅服务于对齐。
unsigned char 类型不允许有 padding bits,C 语言规定 sizeof(unsigned char) 恒等于 1 。其他无符号整数类型可以没有 padding bits。
- 也就是说,对于一个 unsigned char 类型的对象,其取值范围为
有符号整数
对于占用 n × CHAR_BIT 个 bit 位的有符号整数类型 T,这 n × CHAR_BIT 个 bit 分为 sign bit、value bits 和 padding bits 三部分。假设 sign bit + value bits 的个数是 N,则这个 N 是 T 的宽度,说明该有符号整数对象表值范围为 。padding 依旧无人在意。
signed char 类型不允许有 padding bits,C 语言规定 sizeof(signed char) 恒等于 1 。而其他有符号整数类型可以有 padding bits。
那么,考虑司空见惯的 int 类型,又该是怎样的情形?
C 语言规定,int 类型的 sign bit + value bits 长度必须 大于等于 16 (新的INT_WIDTH宏)。相应地,INT_MAX 必须大于等于 32767 ,INT_MIN 必须小于等于 -32768。但除此之外,就没有别的限制了,因此不能假设 sizeof(int) 就一定等于 4,因为有可能存在 padding bits,有些系统(例如 Turbo C)中的 sizeof(int) 就等于 2 。目前主流编译器的 int 类型都没有 padding bits ,但是依然不能断言所有 int 都没有 padding bits 。
intN_t
C 语言标准规定,编译器可以定义一类:
- 没有 padding bits
- 确定宽度
的整数类型 Exact-width integer types ,形如 intN_t ,uintN_t(好想还挺常见的,例如 int16_t)。C 语言标准不要求编译器必须提供 intN_t 类型,但如果编译器提供了宽度为8,16,32 和 64,且没有 padding bits 的整数类型,则应该通过 typedef 提供相应的 intN_t 类型。
例如:某平台 int 类型的宽度是 32 且没有 padding bits,那么就应该通过 typedef int int32_t 定义出 int32_t 类型。
int_leastN_t
C 语言标准规定,编译器需要定义一类宽度至少是某个 N 值的整数类型 Minimum-width integer types ,形如 int_leastN_t ,uint_leastN_t。例如 int_least16_t 意味着这个有符号整数类型的 width 大于等于 16 。
如果编译器定义了 intN_t ,那么 int_leastN_t 和 intN_t 应该一样。
所有编译器都必须定义:
int_least8_t,int_least16_t,int_least32_t,int_least64_t
uint_least8_t,uint_least16_t,uint_least32_t
uint_least64_t
int_fastN_t
C 语言标准规定编译器需要定义一类宽度至少是某个 N 值且处理速度最快的整数类型 Fastest minimum-width integer types ,形如 int_fastN_t ,uint_fastN_t。
这个 fast 并不保证所有情况下处理速度都是最快,编译器可以简单选择满足符号要求和宽度要求的整数类型来进行 typedef。
所有编译器都必须定义:
int_fast8_t,int_fast16_t,int_fast32_t,int_fast64_t
uint_fast8_t,uint_fast16_t,uint_fast32_t,uint_fast64_t
alignment
Alignment 指 对齐要求 。设置对齐要求的动机是:为了 提高访问速度 ,我们在声明对象时对对象首地址的分配做出一定的要求,使得它能够整除某个数,这样子对象在内存中就可以像集装箱那样整齐地垒起来了。对齐值必须是 2 的 n 次方。从这个动机可以看出,对齐的要求和编译器、硬件系统等紧密相关,不同编译器对同样的数据类型可能有不同的对齐要求。
需要注意的是,Alignment 与 sizeof 没有必然联系,它只与编译器或硬件系统的具体实现相关。

对象首地址 % 对象的对齐要求 (Alignment) = 0.
利用 _Alignof(T) 可以获得对象类型 T 的对齐要求(即要求对象首地址能够整除的那个数);利用 _Alignof(O) 可以获得对象 O 的对齐要求。当对象 O 的对齐要求缺省时(即没有自己设置),它等于对象类型 T 的对齐要求。
如果 T 是一个数组类型,元素类型为 E,则 _Alignof(T) = _Alignof(E)。显然,这种计算关系是可以一直递归地算到底的,举例而言:_Alignof(int[3][4][5]) = _Alignof(int[4][5]) = _Alignof(int[5]) = _Alignof(int) 。这一规定消解了数组类型的概念,将对齐规则统一到“一维”,方便了编译器的处理。
C 语言规定,char、signed char 和 unsigned char 享有最弱的对齐要求(weakest alignment requirement),但这个值并不一定就是 1(sizeof char 一定是 1)。这体现的是一个约定问题,是为了给语言将来的发展留下空间,约定死一个数字可能会导致当前有限的认知水平影响了将来的语言迭代发展。
_Alignas 修改对齐要求
C 语言标准规定编译器必须支持的对齐叫做 fundamental alignment,并规定:fundamental alignment <= _Alignof(max_align_t)。max_align_t 是一个类型,拥有最大的基础对齐要求,这个值由具体实现约定,目前主流编译器一般将其约定为 8 或者 16.
当我们声明一个 T 类型的对象 O 时,假使 _Alignof(T) 不能满足我们的要求,我们可以使用 _Alignas(N) T O 为该对象设置一个更大的对齐要求 N( N >= _Alignof(T) ,且 N 必须满足对齐值的要求 => 2 的 n 次方,除此以外没有任何要求。但可以想象,N 要是太大会给机器带来压力)。这说明,_Alignof(O) 并不总是等于 _Alignof(T)。
注意,修改对象的对齐要求不改变对象类型的对齐大小 _Alignof(T),也不会改变对象的大小 sizeof(O) ,只会改变 _Alignof(O)。
结构体类型的对齐要求
当声明一个 T 类型的对象 O,如果 T 是一个结构体类型,成员对象分别是 ,则这个结构体类型 T 的对齐要求是:_Alignof(T) = max{_Alignof(E_i)} ,其中 1 <= i <= 结构体成员个数。这里也有点前面提过的数组的意思,即将对齐要求规约到最低“维数”去。
结构体对象的 size
Size 指对象所占字节的大小,因此考虑这个就可以了,此处我们使用一个叫地址偏移量 offset 的概念来计算结构体对象的 size。结构体第 1 个成员对象 的首地址就是结构体的首地址,此时的地址偏移量 offset 为 0。结构体第 2 个成员对象 的地址偏移量确定方法则如下:
- 首先:offset += sizeof()
- 然后确定 的首地址偏移量:offset += offset % _Alignof() == 0 ? 0 : (_Alignof() - offset % _Alignof())
- 可以看到,当加上了 的 size 后,若当前的 offset 无法满足 的对齐要求,则需要补上一些冗余位使得 的首地址能够满足对齐要求,这些冗余位在前面已经介绍过,称为 internal padding 。
- 注意是按照 对象的对齐要求进行约束的,如果进行过 _Alignas() 要记得考虑
对每个结构体成员,都可以以此类推。处理完所有的结构体成员后,再考虑一下这个结构体对象自己的对齐要求,补上一些冗余位,此时被称为 trailing padding :
- offset += sizeof()
- sizeof(T) = offset + offset (处理完 后得到的) % _Alignof(T) == 0 ? 0 : (_Alignof(T) - offset % _Alignof(T))
- 注意是按照结构体对象类型 T 的对齐要求进行约束的,跟 _Alignas() 无关——这也响应了之前所说的,_Alignas() 只改变对象 O 的对齐要求,不会改变 T 的对齐值和 O 的大小!
- 毕竟对齐要求只约束首地址,对 size 并没有影响。这里用对象类型的对齐要求约束 size 是为了方便处理可能出现的结构体数组 => 这也方便了对数组对象类型对齐要求的理解。
- 注意是按照结构体对象类型 T 的对齐要求进行约束的,跟 _Alignas() 无关——这也响应了之前所说的,_Alignas() 只改变对象 O 的对齐要求,不会改变 T 的对齐值和 O 的大小!
使用函数 offsetof(O) 可以检索对象的地址偏移量 offset。

#pragma pack(n) 调整结构体对象的对齐
这里深入讨论前面提到过的 #pragma pack(n) 。利用它可以调整结构体的对齐要求,具体规则如下:
- #pragma pack(n) 后,对结构体中所有成员 都有:
_Alignof(E_i) = n- 由结构体对象类型的对齐要求规则知,此时
_Alignof(T) = n - pack(n) 针对的是结构体内部的对象对齐要求(也即,结构体内部对象的
_Alignas()会被覆盖),结构体对象不受影响(结构体对象的_Alignas()不会被覆盖)
- 由结构体对象类型的对齐要求规则知,此时


其强大的覆盖功能警示我们不能随意使用 #pragma pack(n) ,除非有确定的需求且充分了解带来的潜在效率风险。
结构体的 lvalue 问题
C 语言标准规定:
- 后跟 ‘.’ 运算符和一个标识符的后缀表达式可以指定一个结构体或者联合体对象的成员,这个表达式的值等于该命名成员的值。如果第一个表达式是左值,则这个后缀表达式也是左值;
- 后跟 ‘->’ 操作符和标识符的后缀表达式也能够指定一个结构体或者联合体对象的成员,这个表达式的值是第一个表达式指向的对象的命名成员的值,是一个左值。
- 如果 f 是一个返回值为结构体或者联合体的函数,并且 x 是该结构体或者联合体的成员,则 f().x 是一个有效的后缀表达式,但不是左值。
malloc 返回的指针对齐
讨论 void* p = malloc(size) : 指针 p 指向的这块内存满足基础对齐要求,因此一般来说 p 的地址 % _Alignof(max_align_t) = 0。如果需要获得指定对齐要求的空间,可以使用: void *aligned_alloc(size_t alignment, size_t size) 。
在这里需要考虑指针的强制转换问题。由于指针的强制转换隐含着地址对应的对象类型发生了变化,因此,如果转换后的指针对应的对象对齐方式不正确,则指针的强制转换行为是未定义行为。举例而言:
